|
|
opentag.com a place for localization tools and technologies |
| \\ XML and Localization :: FAQ :: Presentation | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
You will find here the answers to some of the frequently asked questions about character representation in XML and related technologies. If you find any mistakes or have suggestions for additional useful information, please send an email.
How do I render ruby text?Ruby text is the term used to designate a small annotation associated with a base text. For instance, ruby text is used in East-Asian scripts to provide the pronunciation of ideograph characters. The following example show the Japanese word "日本語" written in kanji and its pronunciation in hiragana:
The term ruby comes from the British name of the smaller font point-size often used for the annotation. Depending on its purpose ruby text is called differently. For instance, in Japanese, the phonetic reading of kanji characters (usually in hiragana) will be called furigana. Depending on the language ruby annotations are placed at different position: above, below, even on the side of each character when the base text is vertical. The implementation of ruby text should follow certain rules to allow for parameters such as where the text should be displayed in reference to its related base text, provide a fallback display if the device used cannot show ruby text properly, and so forth. The W3C provides a set of elements for this: the W3C recommendation for ruby annotation. Example of ruby annotation in XHTML: <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head><title>Ruby Text Examples</title></head>
<body>
<p>Simple ruby text:</p>
<p xml:lang="ja" lang="ja">
<ruby>
<rb>日本語</rb>
<rt>にほんご</rt>
</ruby>
</p>
<p>Ruby text with parenthesis text used if the ruby
function is not implemented:</p>
<p xml:lang="ja" lang="ja">
<ruby>
<rb>日本語</rb>
<rp>[[</rp><rt>にほんご</rt><rp>]]</rp>
</ruby>
</p>
</body>
</html>
Display the document (you need to use a browser that supports XHTML). How do I render bi-directional text?Bi-directional text is used in scripts such as Arabic, Hebrew, Thaana, etc. It is characterized by the fact that some parts of a text run are oriented left-to-right, while others are oriented right-to-left, like, for example, in the following Hebrew sentence:
Do not use Unicode bi-directional markers to specify directionality in
XML. The CSS properties Example of bi-directional style in XHTML: <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head><title>Bi-directional Text</title></head>
<body>
<p lang="he" xml:lang="he"
style="direction: rtl; unicode-bidi: embed">חברת Pepper Creek LLC,
שנוסדה זה-עתה, מונה יותר מ-550 עובדים.</p>
</body>
</html>
Display the document (you need to use a browser that supports XHTML and CSS). How do I render vertical text?Vertical writing is used in different scripts, the most common examples being the East-Asian ones such as Chinese and Japanese. In an XML document where text using either horizontal or vertical display, it is necessary to provide the mechanism to render the text correctly. CSS offers properties to specify text directionality. For most vertical
text use the Example of an XHTML file using the writing-mode property of CSS: <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head><title>Examples with writing-mode</title></head>
<body>
<p style="writing-mode: rl-tb">Example of horizontal text.</p>
<p style="writing-mode: tb-rl">Example of vertical text.</p>
</body>
</html>
Display the document (you need to use a browser that supports XHTML and CSS). How do I render combined text?Combined text is a layout method found in Japanese, where characters are grouped in blocks (kumimoji) or lines (warichu), as shown below:
This feature is supported in XSL-FO and CSS-3 through the The corresponding CSS definitions for rendering these two styles would be, for example: span.kumimoji { text-combine: letters; }
span.warichu { text-combine: lines; }
How do I automate quotation marks?CSS offers a p: { display: block }
autoquote: { display: inline }
autoquote:before { content: open-quote }
autoquote:after { content: close-quote }
*:lang(en) { quotes: "\201C" "\201D" }
*:lang(fr) { quotes: "\AB\A0" "\A0\BB" }
You can then use use the element in your text: <?xml version="1.0" ?> <?xml-stylesheet type="text/css" href="autoquotes.css" ?> <doc xml:lang="fr"> <p id="100">Ali Baba dit: <autoquote>Sésame ouvres-toi!</autoquote></p> </doc> Important warnings:
How do I use the function
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
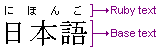
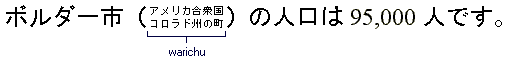
| Type of Numbering | Format | Letter-value | Lang |
|---|---|---|---|
| Thai | ๑ | - | th |
| Classic Greek | א | traditional | el |
| Old Slavic | а | traditional | - |
| Katakana | ア | - | ja |
| Katakana 'Iroha' | イ | - | ja |
| Traditional Hebrew | א | traditional | he |
| Traditional Georgian | ა | traditional | ka |
| Classic Roman | I | - | - |
The attribute lang allows you to specify the language for
the given numbering. Its values are the same as the xml:lang
attribute. Note that the specifications leave discretion to XSL
implementer on which language to support, so there is no guarantee that
any given language is supported by all XSL processors.
For a given XML document as shown below:
<?xml version="1.0" ?> <?xml-stylesheet type="text/xsl" href="xslnumber.xsl" ?> <MyList> <Item>The item</Item> <Item>The item</Item> ...1231 more items... <Item>The item</Item> </MyList>
We can apply this template to get this output. (you need a browser that supports XML and XSL to view this correctly). Note also that depending on the browser (or the version of the browser, or the settings of your system) you may not get support or only partial support for some of the types of output.
How do I use the <xsl:sort/>
element in XML?
The element <xsl:sort/> allows you to specify how
the result of an <xsl:apply-templates> or <xsl:for-each>
element is sorted. You can use several <xsl:sort/>
elements to perform a sort on multiple keys.
The attribute lang specifies the language rules to use for
a given <xsl:sort/> element. The values for lang
are the same as for xml:lang.
<?xml version="1.0" ?> <data> <entry id="100"> <family-name>Øre</family-name> <given-name>Jani</given-name> </entry> <entry id="200"> <family-name>Zorro</family-name> <given-name>Tommie</given-name> </entry> <entry id="300"> <family-name>Zorro</family-name> <given-name>Emilio</given-name> </entry> </data>
The following XSL template will sort in ascending order (default if no order
attribute is specified) the output: by family names, then given names,
respecting the Norwegian sort order, ("Øre" should come after
"Zorro"):
<?xml version="1.0" ?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="data"> <xsl:apply-templates select="entry"> <xsl:sort lang="no" select="family-name"/> <xsl:sort lang="no" select="given-name"/> </xsl:apply-templates> </xsl:template> <xsl:template match="entry"> <p><xsl:value-of select="family-name"/>, <xsl:value-of select="given-name"/></p> </xsl:template> </xsl:stylesheet>
Display the document (you need to use a browser that supports XML and XSL).
How do I separate rendering from tagging?
Text formatting such as bold, italic, underline, etc. may need to different depending on the language of the text. This is especially true for non-Latin based scripts. Separating the tagging of an XML file from its rendering is important to allow an authoring more internationalization-minded.
When defining an XML vocabulary, keep this in mind. For example, the
following excerpt shows an XML document that uses <bold>
to delimit important text:
<para id="100">Some <bold>important</bold> text</para>
Instead, think about the function coded by <bold>
rather than how the output will be rendered. Use a name that conveys that
function:
<para id="100">Some <important>important</important> text</para>
The rendering aspect should be treated separately, in the style-sheet
for example, where the element will be assigned different properties
depending on the language of the text, using, for example,
the
lang() selector of CSS-2:
important:lang(en) { font-weight: bold; }
important:lang(fr) { font-style: italic; }
While having a Western/Latin-centric vision of the output when designing a XML document type does not prevent you to get the correct display ultimately (in general), it will make you less aware of localization issues. Always remember that the source language is "just another language".
Why should I use caution with <br/>
and equivalent elements?
Formatting elements, such as <br/> in XHTML, are to
use with caution because they often break the rule of separating the
content from the rendering/presentation. Using a lot of <br/>
to make a list for example does not make sense: you should use a list and
list items elements.
The bad use of formatting elements does affect the localizability of your files: it may force the translation tools to deal with large paragraphs and hamper the translator to work easily. It may also cause problem with tools that have some limitation on "paragraph" size, and affect adversely segmentation.
For example, the following code is to avoid:
<p> Text of line 1<br/> Text of line 2<br/> Text of line 3</br/> </p>
Instead, use something like this:
<ul> <li>Text of line 1</li> <li>Text of line 2</li> <li>Text of line 3</li> </ul>
Always control the appearance of your text through the style-sheet, not by marking up the document with formatting elements.
Why should I use caution with text-transform
in CSS and XSL?
CSS and XSL offer a property called text-transform that
allows to specify the conversion of a given text into capitalized,
uppercased, or lowercased text.
For example, the following statement will turn the content of any <Section>
element into capitalized text:
Section { text-transform: capitalize }
The current specification allow the user agents that process the
document to "consider the value of text-transform to be none
for characters that are not from the Latin-1 repertoire and for elements
in languages for which the transformation is different from that specified
by the case-conversion tables of ISO 10646".
In practice, this means you cannot rely on text-transform
to make correct conversion for non-Latin-1 characters or even many
languages that use Latin-1 characters but for which the casing or
capitalization rules are complex.
If you choose to use this CSS property, use it with caution and keep in mind the possible changes needed in many localized version of your document. The property is actually deprecated in XSL.
Note that the working draft for CSS3 is much more strict on the implementation of text-transform. So it may become useful at some point, but this will depend a lot on the implementation. For now: avoid to use.
Why should I use caution with absolute positioning in CSS and XSL?
CSS and XSL allow you to specify an element of text to be placed at a specific location of the output. While absolute position may be useful in some cases, it is often a source of problem for localization. A sentence displayed with absolute position might need to be "wrapped" manually, breaking segments without regard for correct segmentation, as shown below:
<div style="position:absolute;top:100;left:50;font-size:11px"> Performance, Adaptability, and Scalability</div> <div style="position:absolute;top:117;left:50;font-size:11px;"> finally meet in one package.</div>
Because the word order in the target languages will be different the source and the translated segments may not correspond anymore. In addition text expansion brings also its set of problem: the whole text needs to be reformatted.
Using absolute positioning for a block of text is similar to adding hard-returns in a plain text file: no translation tool can work with it.